검색결과 리스트
Category에 해당되는 글 72건
- 2009.01.14 IBATIS CLOB처리(flyx)
- 2009.01.06 ROWNUM의 동작 원리와 활용 방법 - 꼭 읽어보길 -
- 2009.01.06 Oracle 날짜 데이터
- 2008.12.09 Toad 기본적인 사용법
- 2008.12.09 Flex3.0 ] Module Class Lv1.
- 2008.12.09 subversion 설치 및 서버 설치 이클립스 연동
- 2008.12.09 이클립스 비주얼에디터 플러그인(스윙플러그인)
- 2008.12.08 자바에서 외부파일 실행
- 2008.12.05 스윙] 웹상의 이미지 경로 로부터 파일저장
- 2008.12.03 Flex3.0] Flex 로그남기기 (spitzer.flair_1.0.3)
글
IBATIS CLOB처리(flyx)
%% 오라클 10g 이상 drive 에서 된다고함 %%
%% Clob 핸들러 없이 일반 select, insert, update, delete 로 처리됨 %%
1. sql-map-config.xml 설정
<dataSource type="DBCP">
<property name="JDBC.Driver" value="${jdbc.driverClassName}"/>
<property name="JDBC.ConnectionURL" value="${jdbc.url}"/>
<property name="JDBC.Username" value="${jdbc.username}"/>
<property name="JDBC.Password" value="${jdbc.password}"/>
<property name="JDBC.DefaultAutoCommit" value="true" />
<property name="Pool.MaximumActiveConnections" value="10"/>
<property name="Pool.MaximumIdleConnections" value="5"/>
<property name="Pool.MaximumCheckoutTime" value="120000"/>
<property name="Pool.TimeToWait" value="500"/>
<property name="Pool.PingQuery" value="select 1 from dual"/>
<property name="Pool.PingEnabled" value="true"/>
<property name="Pool.PingConnectionsOlderThan" value="1"/>
<property name="Pool.PingConnectionsNotUsedFor" value="1"/>
<property name="Driver.SetBigStringTryClob" value="true"/>
</dataSource>
</transactionManager>
2. sqlMap.xml 설정
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE sqlMap PUBLIC "-//iBATIS.com//DTD SQL Map 2.0//EN" "http://www.ibatis.com/dtd/sql-map-2.dtd">
<sqlMap namespace="DOMAIN">
<resultMap id="result_lob_map" class="java.util.HashMap">
<result property="idx_key" column="idx_key" />
<result property="content" column="content" jdbcType="CLOB" javaType="java.lang.String" />
</resultMap>
<select id="select_clob" resultMap="result_lob_map">
SELECT id idx_key, content content FROM CHON
</select>
<insert id="insert_clob" parameterClass="java.util.HashMap" >
insert into CHON(id, content)
values(#id#, #content:java.lang.String#)
</insert>
<update id="update_clob" parameterClass="java.util.HashMap" >
update CHON
set content = #content:java.lang.String#
where id = #id#
</update>
</sqlMap>
select시 resultMap을 이용해서 처리해야한다.
아래 insert부분은 flyx에 포함된 ibatis에서 insert 시 사용된 부분이다.
clob타입이든 varchar 타입이든 다른부분이 없음.
select시에만 상이함.
참고로 altibase5.0에서도 clob처리 방법이 동일함사용방법 동일함
(flex(flyx)+spring+ibatis+altibase경우 위에 첫번째에 해당하는 부분 불필요함)
<resultMap id="ResultClob" class="java.util.HashMap">
<result property="IDX" column="IDX" javaType="String"/>
<result property="TITLE" column="TITLE" javaType="String" />
<result property="CONTENT" column="CONTENT" javaType="java.lang.String" jdbcType="CLOB" />
</resultMap>
<select id="SELECT3" parameterClass="java.util.HashMap" resultMap="ResultClob">
SELECT IDX,TITLE,CONTENT FROM TEST1
</select>
<insert id="INSERT3" parameterClass="java.util.HashMap">
<![CDATA[
INSERT INTO TEST1(IDX,TITLE,CONTENT)
VALUES ((SELECT NVL(MAX(IDX),0)+1 AS IDX FROM TEST),#TITLE#,#CONTENT#)
]]>
</insert>
설정
트랙백
댓글
글
ROWNUM의 동작 원리와 활용 방법 - 꼭 읽어보길 -
ROWNUM의 동작 원리와 활용 방법
ROWNUM은 오라클 데이터베이스가 제공하는 마술과도 같은 컬럼입니다. 이 때문에 많은 사용자들이 문제를 겪기도 합니다. 하지만 그 원리와 활용 방법을 이해한다면 매우 유용하게 사용할 수 있습니다. 필자는 주로 두 가지 목적으로 ROWNUM을 사용합니다.
Top-N 프로세싱: 이 기능은 다른 일부 데이터베이스가 제공하는 LIMIT 구문과 유사합니다.
쿼리 내에서의 페이지네이션(pagination) – 특히 웹과 같은 "stateless" 환경에서 자주 활용됩니다. 필자는 asktom.oracle.com 웹 사이트에서도 이 테크닉을 사용하고 있습니다.
두 가지 활용 방안을 설명하기 전에, 먼저 ROWNUM의 동작 원리에 대해 살펴 보기로 하겠습니다
ROWNUM의 동작 원리
ROWNUM은 쿼리 내에서 사용 가능한 (실제 컬럼이 아닌) 가상 컬럼(pseudocolumn)입니다. ROWNUM에는 숫자 1, 2, 3, 4, ... N의 값이 할당됩니다. 여기서 N 은 ROWNUM과 함께 사용하는 로우의 수를 의미합니다. ROWNUM의 값은 로우에 영구적으로 할당되지 않습니다(이는 사람들이 많이 오해하는 부분이기도 합니다). 테이블의 로우는 숫자와 연계되어 참조될 수 없습니다. 따라서 테이블에서 "row 5"를 요청할 수 있는 방법은 없습니다. "row 5"라는 것은 존재하지 않기 때문입니다.
또 ROWNUM 값이 실제로 할당되는 방법에 대해서도 많은 사람들이 오해를 하고 있습니다. ROWNUM 값은 쿼리의 조건절이 처리되고 난 이후, 그리고 sort, aggregation이 수행되기 이전에 할당됩니다. 또 ROWNUM 값은 할당된 이후에만 증가(increment) 됩니다. 따라서 아래 쿼리는 로우를 반환하지 않습니다.
select *
from t
where ROWNUM > 1;
첫 번째 로우에 대해 ROWNUM > 1의 조건이 True가 아니기 때문에, ROWNUM은 2로 증가하지 않습니다. 아래와 같은 쿼리를 생각해 봅시다.
select ..., ROWNUM
from t
where <where clause>
group by <columns>
having <having clause>
order by <columns>;
이 쿼리는 다음과 같은 순서로 처리됩니다.
1. FROM/WHERE 절이 먼저 처리됩니다.
2. ROWNUM이 할당되고 FROM/WHERE 절에서 전달되는 각각의 출력 로우에 대해 증가(increment) 됩니다.
3. SELECT가 적용됩니다.
4. GROUP BY 조건이 적용됩니다.
5. HAVING이 적용됩니다.
6. ORDER BY 조건이 적용됩니다.
따라서 아래와 같은 쿼리는 에러가 발생할 수 밖에 없습니다.
select *
from emp
where ROWNUM <= 5
order by sal desc;
이 쿼리는 가장 높은 연봉을 받는 다섯 명의 직원을 조회하기 위한 Top-N 쿼리로 작성되었습니다. 하지만 실제로 쿼리는 5 개의 레코드를 랜덤하게(조회되는 순서대로) 반환하고 salary를 기준으로 정렬합니다. 이 쿼리를 위해서 사용되는 가상코드(pseudocode)가 아래와 같습니다.
ROWNUM = 1
for x in
( select * from emp )
loop
exit when NOT(ROWNUM <= 5)
OUTPUT record to temp
ROWNUM = ROWNUM+1
end loop
SORT TEMP
위에서 볼 수 있듯 처음의 5 개 레코드를 가져 온후 바로 sorting이 수행됩니다. 쿼리에서 "WHERE ROWNUM = 5" 또는 "WHERE ROWNUM > 5"와 같은 조건은 의미가 없습니다. 이는 ROWNUM 값이 조건자(predicate) 실행 과정에서 로우에 할당되며, 로우가 WHERE 조건에 의해 처리된 이후에만 increment 되기 때문입니다.
올바르게 작성된 쿼리가 아래와 같습니다.
select *
from
( select *
from emp
order by sal desc )
where ROWNUM <= 5;
위 쿼리는 salary를 기준으로 EMP를 내림차순으로 정렬한 후, 상위의 5 개 레코드(Top-5 레코드)를 반환합니다. 아래에서 다시 설명되겠지만, 오라클 데이터베이스가 실제로 전체 결과 셋을 정렬하지 않습니다. (오라클 데이터베이스는 좀 더 지능적인 방식으로 동작합니다.) 하지만 사용자가 얻는 결과는 동일합니다.
ROWNUM을 이용한 Top-N 쿼리 프로세싱
일반적으로 Top-N 쿼리를 실행하는 사용자는 다소 복잡한 쿼리를 실행하고, 그 결과를 정렬한 뒤 상위의 N 개 로우만을 반환하는 방식을 사용합니다. ROWNUM은 Top- N쿼리를 위해 최적화된 기능을 제공합니다. ROWNUM을 사용하면 대량의 결과 셋을 정렬하는 번거로운 과정을 피할 수 있습니다. 먼저 그 개념을 살펴보고 예제를 통해 설명하기로 하겠습니다.
아래와 같은 쿼리가 있다고 가정해 봅시다.
select ...
from ...
where ...
order by columns;
또 이 쿼리가 반환하는 데이터가 수천 개, 수십만 개, 또는 그 이상에 달한다고 가정해 봅시다. 하지만 사용자가 실제로 관심 있는 것은 상위 N개(Top 10, Top 100)의 값입니다. 이 결과를 얻기 위한 방법에는 두 가지가 있습니다.
클라이언트 애플리케이션에서 쿼리를 실행하고 상위 N 개의 로우만을 가져오도록 명령
• 쿼리를 인라인 뷰(inline view)로 활용하고, ROWNUM을 이용하여 결과 셋을 제한 (예: SELECT * FROM (your_query_here) WHERE ROWNUM <= N)
두 번째 접근법은 첫 번째에 비해 월등한 장점을 제공합니다. 그 이유는 두 가지입니다. 첫 번째로, ROWNUM을 사용하면 클라이언트의 부담이 줄어듭니다. 데이터베이스에서 제한된 결과 값만을 전송하기 때문입니다. 두 번째로, 데이터베이스에서 최적화된 프로세싱 방법을 이용하여 Top N 로우를 산출할 수 있습니다. Top-N 쿼리를 실행함으로써, 사용자는 데이터베이스에 추가적인 정보를 전달하게 됩니다. 그 정보란 바로 "나는N 개의 로우에만 관심이 있고, 나머지에 대해서는 관심이 없다"는 메시지입니다. 이제, 정렬(sorting) 작업이 데이터베이스 서버에서 어떤 원리로 실행되는지 설명을 듣고 나면 그 의미를 이해하실 수 있을 것입니다. 샘플 쿼리에 위에서 설명한 두 가지 접근법을 적용해 보기로 합시다.
select *
from t
order by unindexed_column;
여기서 T가 1백만 개 이상의 레코드를 저장한 큰 테이블이라고, 그리고 각각의 레코드가 100 바이트 이상으로 구성되어 있다고 가정해 봅시다. 그리고 UNINDEXED_COLUMN은 인덱스가 적용되지 않은 컬럼이라고, 또 사용자는 상위 10 개의 로우에만 관심이 있다고 가정하겠습니다. 오라클 데이터베이스는 아래와 같은 순서로 쿼리를 처리합니다.
1. T에 대해 풀 테이블 스캔을 실행합니다.
2. UNINDEXED_COLUMN을 기준으로 T를 정렬합니다. 이 작업은 "full sort"로 진행됩니다.
3. Sort 영역의 메모리가 부족한 경우 임시 익스텐트를 디스크에 스왑하는 작업이 수행됩니다.
4. 임시 익스텐트를 병합하여 상위 10 개의 레코드를 확인합니다.
5.쿼리가 종료되면 임시 익스텐트에 대한 클린업 작업을 수행합니다. .
결과적으로 매우 많은 I/O 작업이 발생합니다. 오라클 데이터베이스가 상위 10 개의 로우를 얻기 위해 전체 테이블을 TEMP 영역으로 복사했을 가능성이 높습니다.
그럼 다음으로, Top-N 쿼리를 오라클 데이터베이스가 개념적으로 어떻게 처리할 수 있는지 살펴 보기로 합시다.
select *
from
(select *
from t
order by unindexed_column)
where ROWNUM < :N;
오라클 데이터베이스가 위 쿼리를 처리하는 방법이 아래와 같습니다.
1. 앞에서와 마찬가지로 T에 대해 풀-테이블 스캔을 수행합니다(이 과정은 피할 수 없습니다).
2. :N 엘리먼트의 어레이(이 어레이는 메모리에 저장되어 있을 가능성이 높습니다)에서 :N 로우만을 정렬합니다.
상위N 개의 로우는 이 어레이에 정렬된 순서로 입력됩니다. N +1 로우를 가져온 경우, 이 로우를 어레이의 마지막 로우와 비교합니다. 이 로우가 어레이의 N +1 슬롯에 들어가야 하는 것으로 판명되는 경우, 로우는 버려집니다. 그렇지 않은 경우, 로우를 어레이에 추가하여 정렬한 후 기존 로우 중 하나를 삭제합니다. Sort 영역에는 최대 N 개의 로우만이 저장되며, 따라서 1 백만 개의 로우를 정렬하는 대신N 개의 로우만을 정렬하면 됩니다.
이처럼 간단한 개념(어레이의 활용, N개 로우의 정렬)을 이용하여 성능 및 리소스 활용도 면에서 큰 이익을 볼 수 있습니다. (TEMP 공간을 사용하지 않아도 된다는 것을 차치하더라도) 1 백만 개의 로우를 정렬하는 것보다 10 개의 로우를 정렬하는 것이 메모리를 덜 먹는다는 것은 당연합니다.
아래의 테이블 T를 이용하면, 두 가지 접근법이 모두 동일한 결과를 제공하지만 사용되는 리소스는 극적인 차이를 보임을 확인할 수 있습니다.
create table t
as
select dbms_random.value(1,1000000)
id,
rpad('*',40,'*' ) data
from dual
connect by level <= 100000;
begin
dbms_stats.gather_table_stats
( user, 'T');
end;
/
Now enable tracing, via
exec
dbms_monitor.session_trace_enable
(waits=>true);
And then run your top-N query with ROWNUM:
select *
from
(select *
from t
order by id)
where rownum <= 10;
마지막으로 상위 10 개의 레코드만을 반환하는 쿼리를 실행합니다.
declare
cursor c is
select *
from t
order by id;
l_rec c%rowtype;
begin
open c;
for i in 1 .. 10
loop
fetch c into l_rec;
exit when c%notfound;
end loop;
close c;
end;
/
이 쿼리를 실행한 후, TKPROF를 사용해서 트레이스 결과를 확인할 수 있습니다. 먼저 Top-N 쿼리 수행 후 확인한 트레이스 결과가 Listing 1과 같습니다.
Code Listing 1: ROWNUM을 이용한 Top-N 쿼리
select *
from
(select *
from t
order by id)
where rownum <= 10
call count cpu elapsed disk query current rows
-------- -------- ------- ------- ------- -------- -------- ------
Parse 1 0.00 0.00 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 2 0.04 0.04 0 949 0 10
-------- -------- ------- ------- ------- -------- -------- ------
total 4 0.04 0.04 0 949 0 10
Rows Row Source Operation
----------------- ---------------------------------------------------
10 COUNT STOPKEY (cr=949 pr=0 pw=0 time=46997 us)
10 VIEW (cr=949 pr=0 pw=0 time=46979 us)
10 SORT ORDER BY STOPKEY (cr=949 pr=0 pw=0 time=46961 us)
100000 TABLE ACCESS FULL T (cr=949 pr=0 pw=0 time=400066 us)
이 쿼리는 전체 테이블을 읽어 들인 후, SORT ORDER BY STOPKEY 단계를 이용해서 임시 공간에서 사용되는 로우를 10 개로 제한하고 있습니다. 마지막 Row Source Operation 라인을 주목하시기 바랍니다. 쿼리가 949 번의 논리적 I/O를 수행했으며(cr=949), 물리적 읽기/쓰기는 전혀 발생하지 않았고(pr=0, pw=0), 불과 400066 백만 분의 일초 (0.04 초) 밖에 걸리지 않았습니다. 이 결과를 Listing 2의 실행 결과와 비교해 보시기 바랍니다.
Code Listing 2: ROWNUM을 사용하지 않은 쿼리
SELECT * FROM T ORDER BY ID
call count cpu elapsed disk query current rows
-------- -------- ------- ------- ------- -------- -------- ------
Parse 1 0.00 0.00 0 0 0 0
Execute 2 0.00 0.00 0 0 0 0
Fetch 10 0.35 0.40 155 949 6 10
-------- -------- ------- ------- ------- -------- -------- ------
total 13 0.36 0.40 155 949 6 10
Rows Row Source Operation
----------------- ---------------------------------------------------
10 SORT ORDER BY (cr=949 pr=155 pw=891 time=401610 us)
100000 TABLE ACCESS FULL T (cr=949 pr=0 pw=0 time=400060 us)
Elapsed times include waiting for the following events:
Event waited on Times
------------------------------ ------------
direct path write temp 33
direct path read temp 5
결과가 완전히 다른 것을 확인하실 수 있습니다. "elapsed/CPU time"이 크게 증가했으며, 마지막 Row Source Operation 라인을 보면 그 이유를 이해할 수 있습니다. 정렬 작업은 디스크 상에서 수행되었으며, 물리적 쓰기(physical write) 작업이 "pw=891"회 발생했습니다. 또 다이렉트 경로를 통한 읽기/쓰기 작업이 발생했습니다. (10 개가 아닌) 100,000 개의 레코드가 디스크 상에서 정렬되었으며, 이로 인해 쿼리의 실행 시간과 런타임 리소스가 급증하였습니다.
ROWNUM을 이용한 페이지네이션
필자가 ROWNUM을 가장 즐겨 사용하는 대상이 바로 페이지네이션(pagination)입니다. 필자는 결과 셋의 로우 N 에서 로우 M까지를 가져오기 위해 ROWNUM을 사용합니다. 쿼리의 일반적인 형식이 아래와 같습니다.
select *
from ( select /*+ FIRST_ROWS(n) */
a.*, ROWNUM rnum
from ( your_query_goes_here,
with order by ) a
where ROWNUM <=
:MAX_ROW_TO_FETCH )
where rnum >= :MIN_ROW_TO_FETCH;
where
여기서,
FIRST_ROWS(N)는 옵티마이저에게 "나는 앞부분의 로우에만 관심이 있고, 그 중 N 개를 최대한 빨리 가져오기를 원한다"는 메시지를 전달하는 의미를 갖습니다.
:MAX_ROW_TO_FETCH는 결과 셋에서 가져올 마지막 로우로 설정됩니다. 결과 셋에서 50 번째 – 60 번째 로우만을 가져오려 한다면 이 값은 60이 됩니다.
:MIN_ROW_TO_FETCH는 결과 셋에서 가져올 첫 번째 로우로 설정됩니다. 결과 셋에서 50 번째 – 60 번째 로우만을 가져오려 한다면 이 값은 50이 됩니다.
이 시나리오는 웹 브라우저를 통해 접속한 사용자가 검색을 마치고 그 결과를 기다리고 있는 상황을 가정하고 있습니다. 따라서 첫 번째 결과 페이지(그리고 이어서 두 번째, 세 번째 결과 페이지)를 최대한 빨리 반환해야 할 것입니다. 쿼리를 자세히 살펴 보면, (처음의 :MAX_ROW_TO_FETCH 로우를 반환하는) Top-N 쿼리가 사용되고 있으며, 따라서 위에서 설명한 최적화된 기능을 이용할 수 있음을 알 수 있습니다. 또 네트워크를 통해 클라이언트가 관심을 갖는 로우만을 반환하며, 조회 대상이 아닌 로우는 네트워크로 전송되지 않습니다.
페이지네이션 쿼리를 사용할 때 주의할 점이 하나 있습니다. ORDER BY 구문은 유니크한 컬럼을 대상으로 적용되어야 합니다. 유니크하지 않은 컬럼 값을 대상으로 정렬을 수행해야 한다면 ORDER BY 조건에 별도의 조건을 추가해 주어야 합니다. 예를 들어 SALARY를 기준으로 100 개의 레코드를 정렬하는 상황에서 100 개의 레코드가 모두 동일한 SALARY 값을 갖는다면, 로우의 수를 20-25 개로 제한하는 것은 의미가 없을 것입니다. 여러 개의 중복된 ID 값을 갖는 작은 테이블을 예로 들어 설명해 보겠습니다.
SQL> create table t
2 as
3 select mod(level,5) id,
trunc(dbms_random.value(1,100)) data
4 from dual
5 connect by level <= 10000;
Table created.
ID 컬럼을 정렬한 후 148-150 번째 로우, 그리고 148–151 번째 로우를 쿼리해 보겠습니다.
SQL> select *
2 from
3 (select a.*, rownum rnum
4 from
5 (select id, data
6 from t
7 order by id) a
8 where rownum <= 150
9 )
10 where rnum >= 148;
ID DATA RNUM
------- ---------- -----------
0 38 148
0 64 149
0 53 150
SQL>
SQL> select *
2 from
3 (select a.*, rownum rnum
4 from
5 (select id, data
6 from t
7 order by id) a
8 where rownum <= 151
9 )
10 where rnum >= 148;
ID DATA RNUM
------- ---------- -----------
0 59 148
0 38 149
0 64 150
0 53 151
로우 148의 경우 DATA=38의 결과가 반환되었습니다. 두 번째 쿼리에서는 DATA=59의 결과가 반환되었습니다. 두 가지 쿼리 모두 올바른 결과를 반환하고 있습니다. 쿼리는 데이터를 ID 기준으로 정렬한 후 앞부분의 147 개 로우를 버린 후 그 다음의 3 개 또는 4 개의 로우를 반환합니다. 하지만 ID에 중복값이 너무 많기 때문에, 쿼리는 항상 동일한 결과를 반환함을 보장할 수 없습니다. 이 문제를 해결하려면 ORDER BY 조건에 유니크한 값을 추가해 주어야 합니다. 위의 경우에는 ROWID를 사용하면 됩니다.
SQL> select *
2 from
3 (select a.*, rownum rnum
4 from
5 (select id, data
6 from t
7 order by id, rowid) a
8 where rownum <= 150
9 )
10 where rnum >= 148;
ID DATA RNUM
------- ---------- -----------
0 45 148
0 99 149
0 41 150
SQL>
SQL> select *
2 from
3 (select a.*, rownum rnum
4 from
5 (select id, data
6 from t
7 order by id, rowid) a
8 where rownum <= 151
9 )
10 where rnum >= 148;
ID DATA RNUM
------- ---------- -----------
0 45 148
0 99 149
0 41 150
0 45 151
이제 쿼리를 반복 실행해도 동일한 결과를 보장할 수 있게 되었습니다. ROWID는 테이블 내에서 유니크한 값을 가집니다. 따라서 ORDER BY ID 조건과 ORDER BY ROWID 기준을 함께 사용함으로써 사용자가 기대한 순서대로 페이지네이션 쿼리의 결과를 확인할 수 있습니다. 다음 단계
ASK Tom
오라클 부사장 Tom Kyte가 까다로운 기술적 문제에 대한 답변을 제공해 드립니다. 포럼의 하이라이트 정보를 Tom의 컬럼에서 확인하실 수 있습니다.
asktom.oracle.com
추가 자료:
Expert Oracle Database Architecture: 9i and 10g Programming Techniques and Solutions
Effective Oracle By Design
ROWNUM 개념 정리
지금까지 ROWNUM에 관련하여 아래와 같은 개념을 설명하였습니다.
ROWNUM의 할당 원리와 잘못된 쿼리 작성을 피하는 방법
ROWNUM이 쿼리 프로세싱에 미치는 영향과 웹 환경의 페이지네이션을 위한 활용 방안
ROWNUM을 이용하여 Top N쿼리로 인한 TEMP 공간의 사용을 피하고 쿼리 응답 속도를 개선하는 방법
설정
트랙백
댓글
글
Oracle 날짜 데이터
날짜 데이터는 DAY단위로 사칙연산된다.
그러면 SYSDATE - 1 은 하루전, 1/24은 1시간전, 1/1440은 1분전이다.
# SYSDATE -- 현시간
# ADD_MONTHS(DATE, 1) -- 한달 더하기
# ADD_MONTHS(DATE, -13) -- 13개월 빼기
# LAST_DAY(SYSDATE) --이번달의 마지막 날짜를 조회한다.
# MONTHS_BETWEEN(SYSDATE, BIRTH_DATE) -- 현재 날짜와 생일과의 개월 간격
# NEXT_DAY(SYSDATE,2) # -- 현재 날짜 다음의 월요일(2)
# ROUND(SYSDATE,'YEAR') -- 현재 날짜를 연도단위로 반올림
# TRUNC(SYSDATE, 'DAY') -- 현재 날짜를 DAY단위로 절삭
하루더하기 ------------------------------------------------ Select sysdate + 1 from dual ------------------------------------------------ 시간더히기 ------------------------------------------------ Select sysdate + 1/24 from dual ------------------------------------------------ 분더하기 ------------------------------------------------ Select sysdate + 1/(24*60) from dual ------------------------------------------------ 초더히기 ------------------------------------------------ Select sysdate + 1/(24*60*60) from dual ------------------------------------------------
EX>
설정
트랙백
댓글
글
Toad 기본적인 사용법
여기 사이트 가시면 동영상 및 관련 문서 얻을수있습니다.
http://www.quest.kr/company/library.aspx
토드 사용법에 대해 알아볼것인데 프로그래밍하면서 필요한 기본적인 것들에 대한 설명들만 하도록 하겠습니다.
스키마 브라우저
- Database-Schema Browser
- 노란박스의 2번째 아이콘
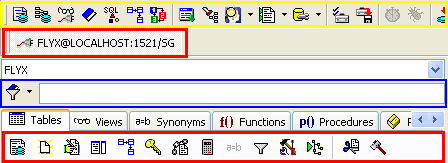
스키마 브라우저는 접속한 DB에 생성된 Table에 대한 정보를 볼수가 있습니다.
첫번째 빨간 박스는 접속한 오라클 정보이며
파란색 박스는 Filter 오브젝트 필터이다.
이 기능은 * 일때는 모든 테이블을 다보여주고 EM으로 시작하는 모든 테이블을 보고 싶으면 EM* 라고 하면
필터링되어 테이블목록이 나타난다.
맨아래 빨간색 박스의 첫번째 아이콘 기능부터 설명하겠다.
아이콘1 - 스크립트 생성 및 클립보드 복사
아래그림의 Execute 버튼을 누르게되면 Sql Statement창이 열리면서 스크립트 내용을 보여주는 기능이다.
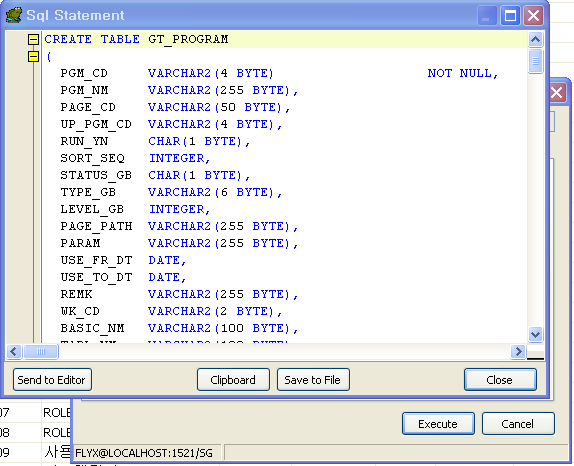
아이콘2 - 새 테이블의 생성
테이블 생성기능 아래 그림처럼 제약조건 테이블명,인덱스 등 테이블 생성하기위한 템플릿 제공
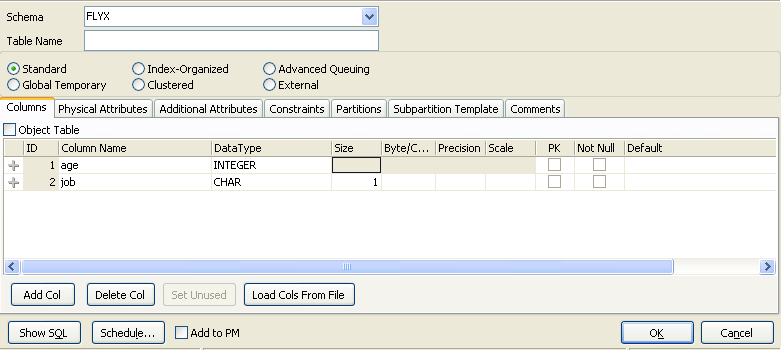
아이콘3 - 테이블 갱신
칼럼의 추가/갱신/제거/스토리지 파라미터의 변경/구성변경/코멘트 추가 등의 기능 지원
아이콘4 - 입력 문장으로 데이터 엑스포트
입력문장의 셋트로써
아이콘5 - ER다이어그램으로써 테이블 보여주기
해당 테이블과 연관된 테이블의 ER 다이어 그램을 보여준다.
아이콘6 - 테이블의 권한과 권한부여의 편집
테이블에 대한 권한을 부여하거나(grant) 회수(revoke)할수 잇는 메뉴이다.
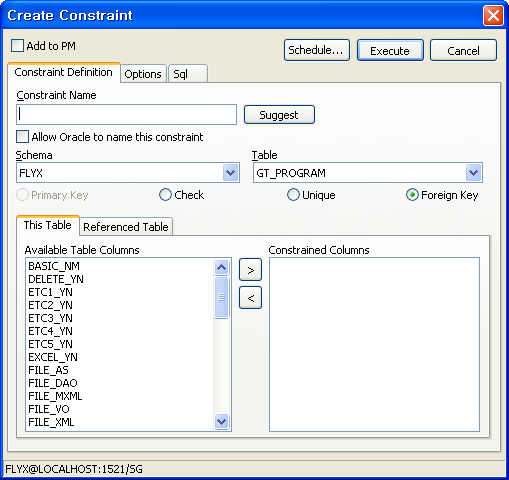
아이콘7 - 테이블에 제약사항 추가하기
아래그림같은 창이 열리면서 테이블에 대한 제약사항을 생성할수있다.
아이콘8 - 테이블 분석
테이블,인덱스 그리고 파티션을 분석하기 위해서 분석테이블 유틸리트를 사용
오라클 데이터베이스에 저장된 체인드로 정보와 분석 테이터를 볼수있다.
아이콘9 - 테이블용 시노님의 생성
테이블 필터기능(현재탭에만영향을 미친다.)
아이콘11 - 테이블 리빌드
아이콘12 - 종속관계의 컴파일
아이콘13 - 테이블 제거(DROP)
아이콘14 - 테이블 제거(truncate)
수정중..............입니다.';;
설정
트랙백
댓글
글
Flex3.0 ] Module Class Lv1.
ModuleClac 클래스는 간단한 수식 계산을 담당하며 메인어플리케이션 클래스에서 모듈을 이용해서
해당 클래스를 로드하여 계산을 처리하는 간단한 예제이다.
ModuleClac.mxml (모듈클래스를 상속)
<mx:Module xmlns:mx="http://www.adobe.com/2006/mxml" layout="absolute" width="400" height="300">
<mx:Script>
<![CDATA[
public function SumClac(m1:Number, m2:Number):Number{
return m1+m2;
}
]]>
</mx:Script>
</mx:Module>
ModuleTest.mxml (모듈테스트 apllication)
<mx:Application xmlns:mx="http://www.adobe.com/2006/mxml" layout="vertical">
<mx:Script>
<![CDATA[
import mx.core.IFlexModuleFactory;
import mx.modules.IModuleInfo;
import mx.modules.ModuleManager;
private var obModule:Object;
public var iModuleInfo:IModuleInfo;
public var iReadImg:IReadImg;
/*
Module swf를 설정해서 모듈 정보 객체를 생성
Module 정보 객체는 로더객체라고 생각하면됨
*/
private function GetModule(mURL:String):void{
iModuleInfo = ModuleManager.getModule(mURL);
iModuleInfo.addEventListener("ready",fnReady);
iModuleInfo.load();
}
private function fnReady(e:Event):void{
e.target.removeEventListener("ready",fnReady);
/*
모듈정보객체에게 다운받은 모듈을 생성
생성객체는 object로 변수에 저장한다.
*/
obModule = iModuleInfo.factory.create();
tiResult.text = obModule.SumClac(10,30).toString();
}
]]>
</mx:Script>
<mx:TextInput x="27" y="19" width="93" id="tiResult"/>
<mx:Image id="imgView" width="300" height="200"/>
<mx:Button x="128" y="19" label="ModuleLoad" click="GetModule('ModuleClac.swf')"/>
</mx:Application>
첫번째 모듈클래스는 모듈클래스를 상속받아 만든 클래스입니다.
일반적으로 모듈클래스를 상속받는 이유는 컴포너트를 배치하는 목적입니다.
그러나 위에 예의 경우 단순한 로직처리를 위한 부분밖에 없기 때문에 컴포넌트를 배치할수잇는 모듈클래스보다 가벼운
ModuleBase라는 클래스를 상속받아 처리하는 SimpleClass.as 입니다.
import flash.events.Event;
import mx.core.Application;
import mx.modules.ModuleBase;
public class SimpleClass extends ModuleBase{
public function SimpleClass(){}
public function SumClac(m1:Number, m2:Number):Number{
return m1+m2;
}
}
}
중요한것은 위의 코드를 테스트 하기 위해서는 as파일을 swf로 변환시켜줘야 합니다.
그러기 위해서는 이클립스에서 약간의 작업이 필요합니다.
프로젝트에서 마우스오른쪽버튼클릭후 properties
아래그림에서 add하여 아까작성한 as 및 mxml을 선택하면 이클립스에서 swf로 파일을 자동적으로 생성해줍니다.

설정
트랙백
댓글
글
subversion 설치 및 서버 설치 이클립스 연동
Step1 다운로드.
1. 아래 주소 or 첨부파일에서 다운로드
http://subversion.tigris.org/servlets/ProjectDocumentList?folderID=91
2. 현재 (2008년 11월 22일) 최신 버젼인 1.5.3 을 받자. (아래 캡쳐 화면 참조)
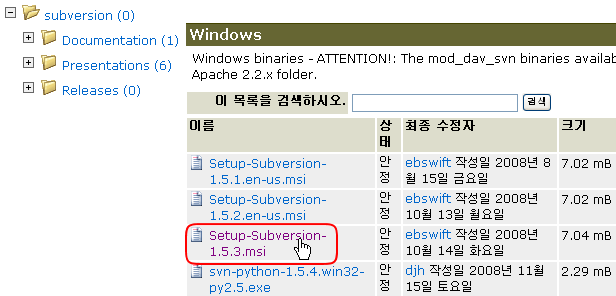
Step2 서버설치.
 setup-subversion-1.5.3.part1-sungback.exe
setup-subversion-1.5.3.part1-sungback.exe setup-subversion-1.5.3.part2-sungback.rar
setup-subversion-1.5.3.part2-sungback.rar1. 다운받은 subversion 설치 파일을 더블 클릭해서 설치한다.
[Next] 만 계속 누르면 설치된다.
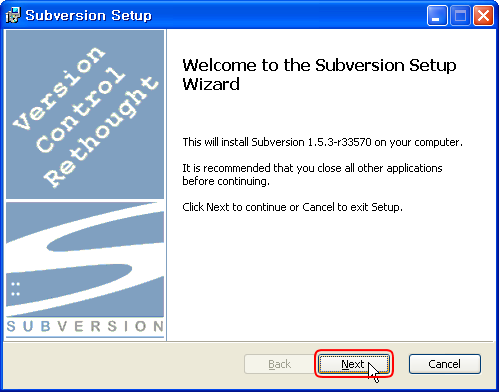
2. C: 드라이브에 svnrepos 라는 폴더를 생성한다. (폴더명은 자유롭게 정해도 된다.)
명령 프롬프트를 실행해서 C:\svnrepos 라는 폴더로 이동한다.
C:\svnrepos>svnadmin create c:\svnrepos
위의 명령을 실행하면 아래의 캡쳐와 같은 폴더들이 생성된다.
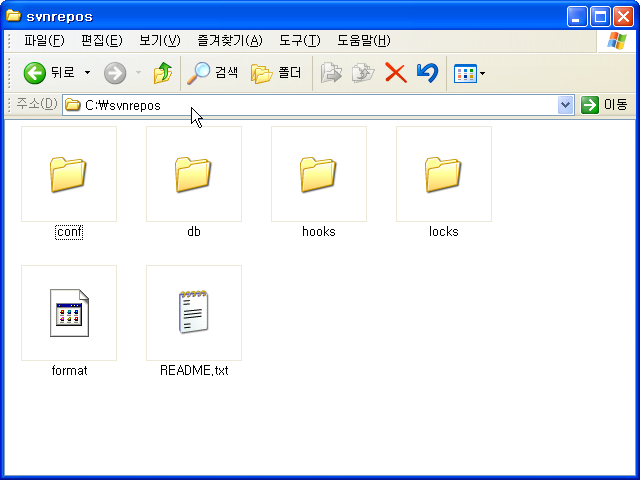
3. conf 폴더로 이동하면 아래의 캡쳐와 같은 파일들이 보인다.
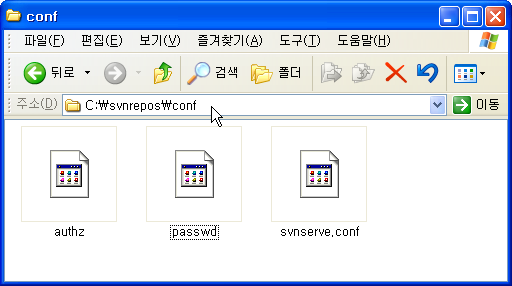
3-1. svnserve.conf 파일을 열어서 아래와 같이 편집한다.
( C:\svnrepos\conf\svnserve.conf )
[general]
anon-access = read
auth-access = write
password-db = passwd
↑ 위의 뜻
anon-access = read 는 인증되지 않은 사용자는 읽기만 가능. (접근 못하게 하려면 none)
auth-access = write 는 인증된 사용자는 쓰기도 가능
3-2. 같은 conf 폴더의 passwd 파일의 내용을 아래와 같이 편집한다. (참고 : 파일 확장자가 없다.)
( C:\svnrepos\conf\passwd )
[users]
hong = hongpass
jang = jangpass
Step3 서버자동실행설정(옵션).
Subversion 서버를 자동 실행해주는 유틸리티를 설치하여 자동 실행해보자.
1. 다운로드 주소 : http://www.pyrasis.com/main/SVNSERVEManager
프로그램의 제목은 SVNSERVE Manager 이고 우리나라 개발자 분이 만들었네요!!!
사용해보고 좋으면 위의 싸이트에 가서 감사 인사 정도는 남겨주세요.
SVNManager-1.1.1-Setup.msi 를 다운받고 더블 클릭해서 설치.
[Next] 계속 클릭 설치 완료!
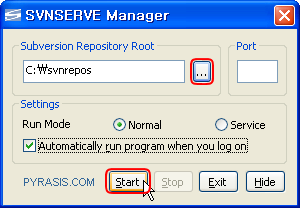
2. 바탕화면의 SVNSERVE Manager 를 더블 클릭하여 실행.
2-1. [...] 버튼 클릭한 후 subversion 에서 설정한 C:\svnrepos 폴더를 지정.
2-2. Automatically run program when you log on 선택해서 자동 실행 설정.
2-3. [Start] 버튼 클릭. 시작.
2-4. [Hide] 버튼 클릭하면 트레이 아이콘으로 숨는다.
[출처] [소스 관리] Subversion 서버 다운로드|작성자 메멘토
이클립스와 subversion 연동방법(옵션)
- Search for new features to install 버튼 선택 후 Next 클릭.
- 없을 경우 New Remote Site 추가(Name : subclipse, URL : http://subclipse.tigris.org/update).
- finish 클릭.
- 자동으로 Eclipse에서 http://subclipse.tigris.org/update 사이트에 접속하여 패키지 다운로드 수행함.
- 패키지 전부 다운 받으면 Install All 클릭을 통해 설치함.
- 설치가 완료되면 재시작 버튼을 클릭하여 이클립스 재시작함.
- window->preferences에 Team부분을 보면 다음처럼 SVN관련이 추가된 것을 볼 수 있음.
- 선택하면 SVN repositories 화면에 생성됨.
- SVN repositories 화면에서 마우스 오른쪽을 클릭해서 new>repository location으로 새 저장소를 생성한다.
- http://www.mimul.com/svn/sample URL 등록하고 mimuluser/패스워드를 기입하고 Finish를 클릭함.
- VN repositories에 해당 svn이 나타남.
- Project에서 마우스 오른쪽 클릭>Team>Shared Project 클릭
- 셋팅이 되어 있는 SVN repository를 선택하면 된다. (만약 접근 오류가 나오면 workspace 디렉토리 속성의 읽기 전용인지 확인하여 해제를 해줌)
- Select All을 클릭하여 해당 프로젝트의 모든 파일을 선택하여 Commit을 수행함.
설정
트랙백
댓글
글
이클립스 비주얼에디터 플러그인(스윙플러그인)
이클립스 비주얼 에디터(Visual Editor) 플러그인 다운로드 및 설정 방법
이클립스 WTP 2.0.1 (이클립스 3.3 Europa 유로파 버젼) 이라고 가정하고 설명한다.
1. 플러그인을 다운로드 한다.
유로파 용(3.3) 다운로드 => : http://www.ehecht.com/eclipse_ve/ve_eclipse_33_v200709242300_win.zip
가니메데 용(3.4) 다운로드 => : http://www.ehecht.com/eclipse_ve/ve_eclipse_34_200807092330_win.zip
2. 다운로드 결과.
ve_eclipse_33_v200709242300_win.zip 파일을 여기서는 바탕 화면에 다운 받았다.
3. 압축 해제
해제하면 features 와 plugins 폴더가 나온다.

4. 이클립스 설치 폴더에 features 와 plugins 폴더를 붙여넣기 한다. (예 : C:\eclipse 에 붙여넣기 한다.)
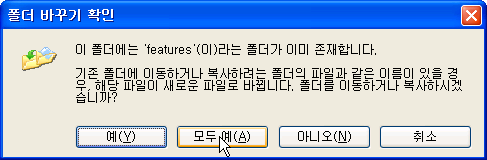
(주의 사항 : 이 때 꼭 이클립스를 종료한 후 붙여넣기를 해야 한다. 실행 상태에서 하면 오류 발생할 수 있다.)
이 때 같은 폴더가 있기 때문에 메세지 상자가 뜨는데 [모두 예] 를 선택해주면 된다.
설치 완료.
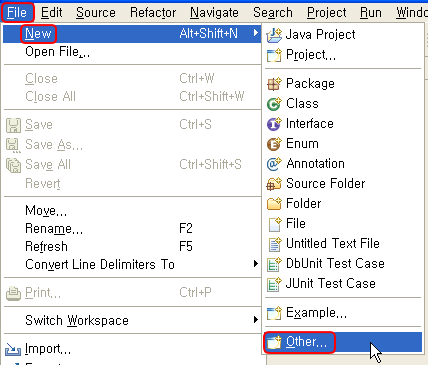
5. Visual Editor 를 사용해 보자.
File -> New -> Other 선택한다.
6. 스크롤해서 Java -> Visual Class 선택 -> [Next] 클릭
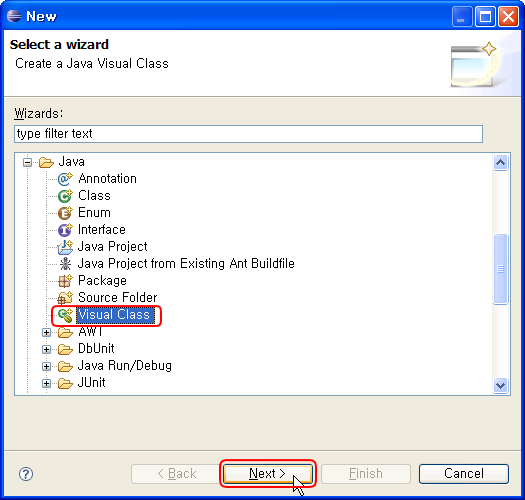
7. 소스를 만들어보자.
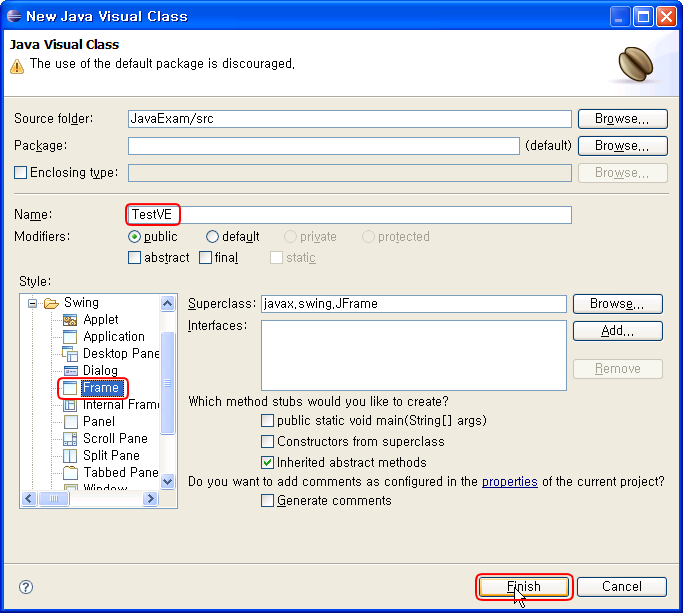
Name : TestVE 라고 하고, Swing 의 Frame 을 상속 받고, [Finish]
8. 최종 결과 화면 (Palette 를 보려면 에디터 창의 오른쪽 부분의 ◁ 을 클릭하면 된다.)
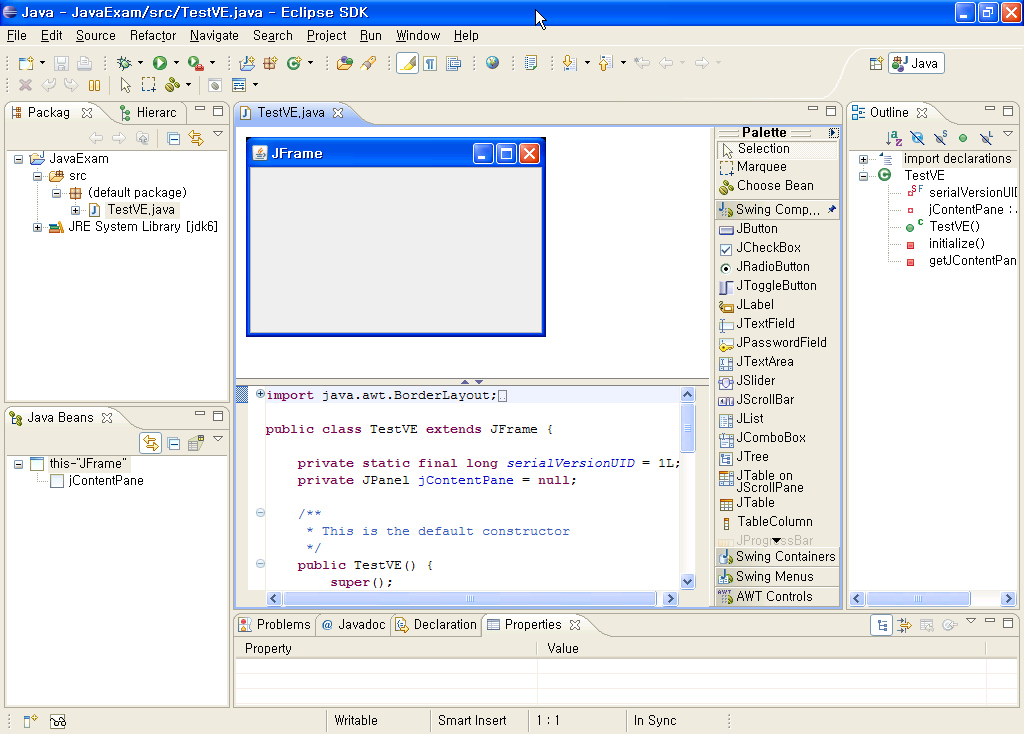
끝. Visual Editor 를 사용해서 GUI 프로그래밍을 편하게 해보자^^
설정
트랙백
댓글
글
자바에서 외부파일 실행
java.lang
클래스 Runtime
java.lang.Objectjava.lang.Runtime
자바에서 외부파일을 실행시키기 위해 사용되는 Runtime클래스
오버로딩 되어잇는 exec()메소드
Process |
exec (String command) 지정된 캐릭터 라인 커멘드를, 독립한 프로세스로 실행합니다. |
Process |
exec (String [] cmdarray) 지정된 커멘드와 인수를, 독립한 프로세스로 실행합니다. |
Process |
exec (String [] cmdarray, String [] envp) 지정된 커멘드와 인수를, 지정된 환경을 가지는 독립한 프로세스로 실행합니다. |
Process |
exec (String [] cmdarray, String [] envp, File dir) 지정된 커멘드와 인수를, 지정된 환경과 작업 디렉토리를 가지는 독립한 프로세스로 실행합니다. |
Process |
exec (String command, String [] envp) 지정된 캐릭터 라인 커멘드를, 지정된 환경을 가지는 독립한 프로세스로 실행합니다. |
Process |
exec (String command, String [] envp, File dir) 지정된 캐릭터 라인 커멘드를, 지정된 환경과 작업 디렉토리를 가지는 독립한 프로세스로 실행합니다. |
void |
exit (int status) 현재 실행하고 있는 Java 가상 머신을, 종료 순서를 개시해 종료합니다. |
자바에서 특정 외부파일을 실행시키기 위한 예제입니다.
방법1.
import java.io.InputStreamReader;
public class ProcessTest {
public static void main(String args[]) throws Exception{
Process p=Runtime.getRuntime().exec("C:/1.exe");
BufferedReader bf=new BufferedReader(new InputStreamReader(p.getErrorStream()));
String str="";
while((str=bf.readLine())!=null){
System.out.println(str);
}
BufferedReader bf1=new BufferedReader(new InputStreamReader(p.getInputStream()));
String str1="";
while((str1=bf1.readLine())!=null){
System.out.println(str1);
}
}
}
위의 내용을 클래스화 시켜서 별도의 클래스로 작성!
public class Executor
{
public static void execute(String command)
{
try
{
String cmd[] = new String[3];
cmd[0] = "cmd.exe";
cmd[1] = "/C";
cmd[2] = command;
Runtime rt = Runtime.getRuntime();
System.out.println("Execing " + cmd[0] + " " + cmd[1] + " " + cmd[2]);
Process proc = rt.exec(cmd);
StreamGobbler errorGobbler = new StreamGobbler(proc.getErrorStream(), "ERROR");
StreamGobbler outputGobbler = new StreamGobbler(proc.getInputStream(), "OUTPUT");
errorGobbler.start();
outputGobbler.start();
int exitVal = proc.waitFor();
System.out.println("ExitValue: " + exitVal);
}
catch(Throwable t)
{
t.printStackTrace();
}
}
}
설정
트랙백
댓글
글
스윙] 웹상의 이미지 경로 로부터 파일저장
/*
웹상의 image url경로를 적어주게 되면 그 경로를 바탕으로 이미지를 로컬에 저장시켜주는 기능입니다.
아래 saveMethod는 다른이름으로 저장 버튼을 눌렀을시 이벤트가 발생하는 메서드입니다.
sava부분 로직만 참고!!
*/
private void savaMethod(java.awt.event.ActionEvent evt) {
/*===============================================================
* url_tf에 입력된 문자열을 가져온다. 그리고 그것이 비었는지 비교한후
* 저장할수 있는 JFileChooser를 생성한다.
* ==============================================================
*/
String url_path = url_tf.getText().trim();
if(url_path.length()>0){
JFileChooser fc = new JFileChooser("c:"+System.getProperty("file.separator"));
/*
* 저장시 JFilechooser창에 파일명이 설정되도록 하는 부분
*/
String f_name = url_path.substring(url_path.lastIndexOf("/")+1);
File set_name = new File("C:"+System.getProperty("file.separator")+f_name);
fc.setSelectedFile(set_name); // JFileChooser 창열릴시 파일명을 표시
int cmd = fc.showSaveDialog(this);
if(cmd==JFileChooser.APPROVE_OPTION){
/*
* 실제 저장할 파일은 웹상에 존재한다. 그것과
* 연결하여 현재 소스로 자원을 읽어올 통로(배관)이 필요한다.
* 웹사이트 문서와 연결이기 때문에 url객체 생성
*/
InputStream input = null;
FileOutputStream fos = null;
try {
input = new URL(url_path).openStream();
File f = fc.getSelectedFile();
/* =============================================================
* 이제 위에서 선택된 파일과 통로을 연결하여 자원들을 저장할수 있도록
* 배관작업을 한다.
* =============================================================
*/
if (f.exists()) {
int ch = JOptionPane.showConfirmDialog(this, "덮어씌우겠습니까?");
if (ch == JOptionPane.CANCEL_OPTION) {
return;
}
}
/*
* ==========================================================
* 현재행에 제어가 넘어왔다면 파일이 존재하지 않거나 존재하더라도
* 덮어씌우기를 선택한 경우이다.
* ==========================================================
*/
fos = new FileOutputStream(f);
//FileOutputStream을 통하여 파일에 쓰기
byte[] buf = new byte[2048];
int size = -1;
while((size = input.read(buf))!=-1){
fos.write(buf, 0, size);
}
JOptionPane.showMessageDialog(this, "저장완료!!");
} catch (Exception ex) {
} finally {
try {
fos.close();
} catch (IOException ex) {
}
}
}
}
}
설정
트랙백
댓글
글
Flex3.0] Flex 로그남기기 (spitzer.flair_1.0.3)
Flex에서 디버그 플레이어가 설치하고 trace()하게 되면 로그를 찍게 되는데
플러그인을 설치하여 좀더 편한방법으로 사용할수 있다.
우선적으로 자신이 디버그플레이어를 사용하고 있는지 확인해보자!!
http://kb.adobe.com/selfservice/viewContent.do?externalId=tn_15507&sliceId=1
아래처럼 yes라고 나오면 정상적으로 설치된것인다.
yes라고 나오는 사람은 저아래부분으로 건너띄어서 설치부분만 보면될것이다.
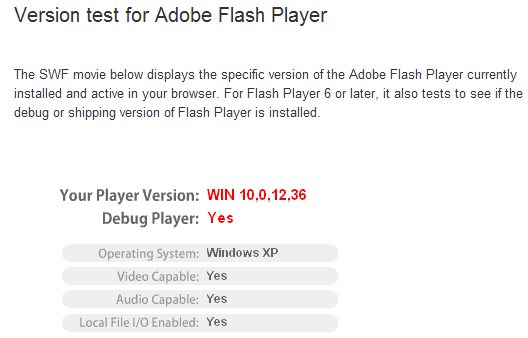
만약 No라고 나오는 사람은 디버그 플레이를 삭제하고 재설치해야된다.
※ 인터넷 브라우져를 닫고 시도하는것을 권장 종종 위에대로 햇는데도 안된다고 하는 사람있다;;
플레이서 삭제 uninstaller :
http://download.macromedia.com/pub/flashplayer/current/uninstall_flash_player.exe
레지스트리 삭제
시작 - 실행 - regedit - ctrl+F(편집-찾기) - SafeVersions 입력 - 찾으면 해당 폴더삭제
디버그플레이어 재설치 :
http://kb.adobe.com/selfservice/viewContent.do?externalId=tn_14266&sliceId=2
10디버그 플레이어(26M) 다운로드 후에 압축풀면된다.
그러면 여러개 파일이 나오는데 그중에서 flashplayer10r12_36_winax_debug.exe 를 실행하여 설치하면된다.
위에 작업 완료후에도 디버그플레이어 확인 페이지에서 NO로 나오게되면 인터넷 브라우져를 닫고 시도하면 정상적으로 될것이다.
============================= 여기까지는 거의 잡설이였습니다. =======================================
/* 이클립스 종료상태에서 하시면 될듯합니다. */
 spitzer.flair_1.0.3-jiyh78.zip
spitzer.flair_1.0.3-jiyh78.zip위의 파일을 일단 다운받은후 압축을 해제한다.
압축해제하면 폴더가 하나 나오는데 그 폴더를 plugin폴더에 넣으면된다.
빌더를 사용하는사람은 플렉스 빌더의 plugin폴더에 넣고 이클립스 플러그인버전을 사용하는 사람은 이클립스 plugin폴더에 넣으면된다.
step1.
각자 자신에 맞는 사용자계정폴더로 이동후 ( C:\Documents and Settings\사용자계정 ) mm.cfg파일을
하나 만든다. 그냥 메모장 열어서
ErrorReportingEnable=1
TraceOutputFileEnable=1
위와 같은 내용을 적고 저장할대 mm.cfg로 저장하면된다.
ex> C:\Documents and Settings\dh
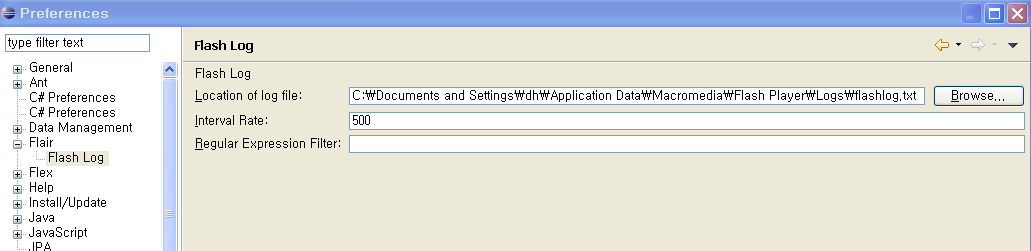
location에 아래내용 복사해서 넣으면된다..
그냥 폴더로 보면 보이지 않으니 아래 dh부분만 자신에 맞는것으로 바꾸로 복사해서 넣으면된다.
C:\Documents and Settings\dh\Application Data\Macromedia\Flash Player\Logs\flashlog.txt
이렇게 하면 모든것이 완료된것인다.
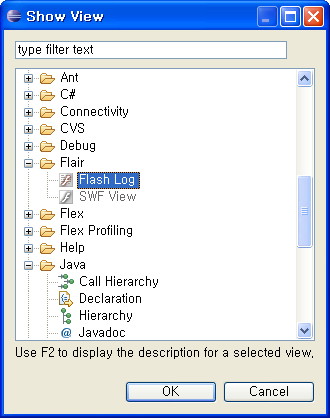
이클립스에서 아래처럼 FlashLog를 선택하게 되면 이클립스 하단탭에 Flash Log가 나타난다.
그러면 trace()된 부분이 모드 그 화면에 찍혀서 보이게 된다...

RECENT COMMENT